




 Qzone
Qzone
 微博
微博
 微信
微信
编者按:目前,基于神经网络的端到端文本到语音合成技术发展迅速,但仍面临不少问题——合成速度慢、稳定性差、可控性缺乏等。为此,浙大一知智能研究中心联合微软亚洲研究院机器学习组和微软(亚洲)互联网工程院语音团队提出了一种基于Transformer的新型前馈网络FastSpeech,兼具快速、鲁棒、可控等特点。与自回归的Transformer TTS相比,FastSpeech将梅尔谱的生成速度提高了近270倍,将端到端语音合成速度提高了38倍,单GPU上的语音合成速度达到了实时语音速度的30倍。
近年来,基于神经网络的端到端文本到语音合成(Text-to-Speech,TTS)技术取了快速发展。与传统语音合成中的拼接法(concatenative synthesis)和参数法(statistical parametric synthesis)相比,端到端语音合成技术生成的声音通常具有更好的声音自然度。但是,这种技术依然面临以下几个问题:
合成语音的速度较慢
端到端模型通常以自回归(Autoregressive)的方式生成梅尔谱(Mel-Spectrogram),再通过声码器(Vocoder)合成语音,而一段语音的梅尔谱通常能到几百上千帧,导致合成速度较慢;
合成的语音稳定性较差
端到端模型通常采用编码器-注意力-解码器(Encoder-Attention-Decoder)机制进行自回归生成,由于序列生成的错误传播(Error Propagation)以及注意力对齐不准,导致出现重复吐词或漏词现象;
缺乏可控性
自回归的神经网络模型自动决定一条语音的生成长度,无法显式地控制生成语音的语速或者韵律停顿等。
为了解决上述的一系列问题,浙大一知人工智能研究中心联合微软亚洲研究院机器学习组和微软(亚洲)互联网工程院语音团队提出了一种基于Transformer的新型前馈网络FastSpeech,可以并行、稳定、可控地生成高质量的梅尔谱,再借助声码器并行地合成声音。
在LJSpeech数据集上的实验表明,FastSpeech除了在语音质量方面可以与传统端到端自回归模型(如Tacotron2和Transformer TTS)相媲美,还具有以下几点优势:
快速:与自回归的Transformer TTS相比,FastSpeech将梅尔谱的生成速度提高了近270倍,将端到端语音合成速度提高了近38倍,单GPU上的语音合成速度是实时语音速度的30倍;
鲁棒:几乎完全消除了合成语音中重复吐词和漏词问题;
可控:可以平滑地调整语音速度和控制停顿以部分提升韵律。
模型框架
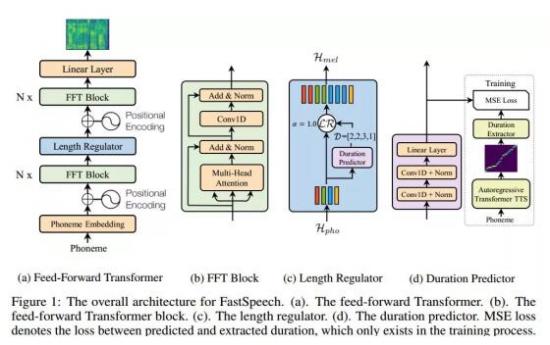
前馈Transformer架构
FastSpeech采用一种新型的前馈Transformer网络架构,抛弃掉传统的编码器-注意力-解码器机制,如图1(a)所示。其主要模块采用Transformer的自注意力机制(Self-Attention)以及一维卷积网络(1D Convolution),我们将其称之为FFT块(Feed-Forward Transformer Block, FFT Block),如图1(b)所示。前馈Transformer堆叠多个FFT块,用于音素(Phoneme)到梅尔谱变换,音素侧和梅尔谱侧各有N个FFT块。特别注意的是,中间有一个长度调节器(Length Regulator),用来调节音素序列和梅尔谱序列之间的长度差异。
长度调节器
长度调节器如图1(c)所示。由于音素序列的长度通常小于其梅尔谱序列的长度,即每个音素对应于几个梅尔谱序列,我们将每个音素对齐的梅尔谱序列的长度称为音素持续时间。长度调节器通过每个音素的持续时间将音素序列平铺以匹配到梅尔谱序列的长度。我们可以等比例地延长或者缩短音素的持续时间,用于声音速度的控制。此外,我们还可以通过调整句子中空格字符的持续时间来控制单词之间的停顿,从而调整声音的部分韵律。
音素持续时间预测器
音素持续时间预测对长度调节器来说非常重要。如图1(d)所示,音素持续时间预测器包括一个2层一维卷积网络,以及叠加一个线性层输出标量用以预测音素的持续时间。这个模块堆叠在音素侧的FFT块之上,使用均方误差(MSE)作为损失函数,与FastSpeech模型协同训练。我们的音素持续时间的真实标签信息是从一个额外的基于自回归的Transformer TTS模型中抽取encoder-decoder之间的注意力对齐信息得到的,详细信息可查阅文末论文。
实验评估
为了验证FastSpeech模型的有效性,我们从声音质量、生成速度、鲁棒性和可控制性几个方面来进行了评估。
声音质量
我们选用LJSpeech数据集进行实验,LJSpeech包含13100个英语音频片段和相应的文本,音频的总长度约为24小时。我们将数据集分成3组:300个样本作为验证集,300个样本作为测试集,剩下的12500个样本用来训练。
我们对测试样本作了MOS测试,每个样本至少被20个英语母语评测者评测。MOS指标用来衡量声音接近人声的自然度和音质。我们将FastSpeech方法与以下方法进行对比:1) GT, 真实音频数据;2) GT (Mel + WaveGlow), 用WaveGlow作为声码器将真实梅尔谱转换得到的音频;3) Tacotron 2 (Mel + WaveGlow);4) Transformer TTS (Mel + WaveGlow);5) Merlin (WORLD), 一种常用的参数法语音合成系统,并且采用WORLD作为声码器。
从表1中可以看出,我们的音质几乎可以与自回归的Transformer TTS和Tacotron 2相媲美。

合成速度
我们比较FastSpeech与具有近似参数量的Transformer TTS的语音合成速度。从表2可以看出,在梅尔谱的生成速度上,FastSpeech比自回归的Transformer TTS提速将近270倍;在端到端(合成语音)的生成速度上,FastSpeech比自回归的Transformer TTS提速将近38倍。FastSpeech平均合成一条语音的时间为0.18s,由于我们的语音平均时长为6.2s,我们的模型在单GPU上的语音合成速度是实时语音速度的30倍(6.2/0.18)。
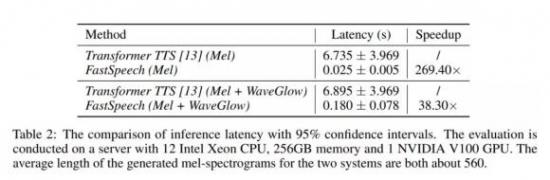
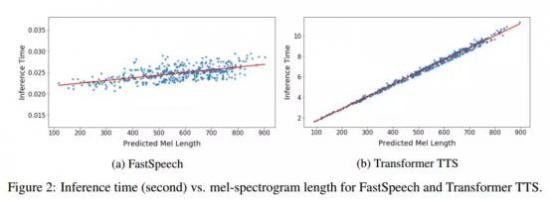
图2展示了测试集上生成语音的耗时和生成的梅尔谱长度(梅尔谱长度与语音长度成正比)的可视化关系图。可以看出,随着生成语音长度的增大,FastSpeech的生成耗时并没有发生较大变化,而Transformer TTS的速度对长度非常敏感。这也表明我们的方法非常有效地利用了GPU的并行性实现了加速。
鲁棒性
自回归模型中的编码器-解码器注意力机制可能导致音素和梅尔谱之间的错误对齐,进而导致生成的语音出现重复吐词或漏词。为了评估FastSpeech的鲁棒性,我们选择微软(亚洲)互联网工程院语音团队产品线上使用的50个较难的文本对FastSpeech和基准模型Transformer TTS鲁棒性进行测试。从下表可以看出,Transformer TTS的句级错误率为34%,而FastSpeech几乎可以完全消除重复吐词和漏词。

语速调节
FastSpeech可以通过长度调节器很方便地调节音频的语速。通过实验发现,从0.5x到1.5x变速,FastSpeech生成的语音清晰且不失真。
消融对比实验
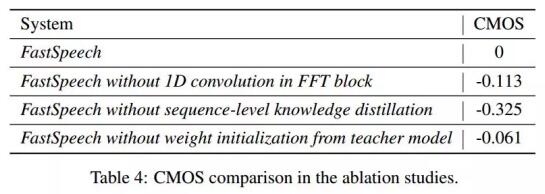
我们也比较了FastSpeech中一些重要模块和训练方法(包括FFT中的一维卷积、序列级别的知识蒸馏技术和参数初始化)对生成音质效果的影响,通过CMOS的结果来衡量影响程度。由下表可以看出,这些模块和方法确实有助于我们模型效果的提升。
未来,我们将继续提升FastSpeech模型在生成音质上的表现,并且将会把该模型应用到其它语言(例如中文)、多说话人和低资源场景中。我们还会尝试将FastSpeech与并行神经声码器结合在一起训练,形成一个完全端到端训练的语音到文本并行架构。
我们也将在不久后开放论文源代码,敬请关注!
浙大一知智能联合研究院介绍:
浙大一知智能联合研究院是由一知智能科技与浙大联合成立的研究机构,目前拥有近30人的人工智能算法研发团队,均为研究生以上学历,且有10余名计算机专业博士,研究方向包括自然语言理解、语音识别、语音合成等人工智能前沿领域,旨在打造语音人机交互闭环生态。




安兔兔2022-05-25 20:4405-25 20:44

娱乐中国2022-05-25 20:2805-25 20:28

电影界2022-05-25 20:1905-25 20:19

电影界2022-05-25 20:1505-25 20:15

电影界2022-05-25 20:1505-25 20:15

新娱在线2022-05-25 20:1005-25 20:10

南方娱乐网2022-05-25 20:0605-25 20:06

电影界2022-05-25 19:5705-25 19:57






 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>













 京公网安备
京公网安备 网上有害信息
网上有害信息 12321垃圾信息
12321垃圾信息 北京市互联网举报
北京市互联网举报