Qzone
Qzone
 微博
微博
 微信
微信
在最近由AspenCore主办的2023中国IC领袖峰会上,中国半导体行业协会IC设计分会理事长魏少军教授在《集成电路发展中的“正”与“奇”》的主题演讲中提到,中国半导体产业的发展要在“守正”的市场发展道路上稳步前行,同时也需要在新的赛道“出奇”。比如在高性能计算领域,在先进工艺、技术和芯片产品受到外界限制的情况下,我们如何利用国产工艺技术实现创新而跟全球高性能计算和AI发展保持同步甚至超越?
更具体一点,就目前炒作火热的AIGC大模型所需要的大算力AI芯片来说,能否利用我们现在可用的工艺和技术来开发在性能上可以跟英伟达GPGPU对标的AI芯片呢?一些“守正且出奇”的技术包括:软件定义芯片、chiplet、3D堆叠和先进封装、存算一体等。
自从OpenAI的ChatGPT于2022年11月推出以来,AIGC迅速在全球掀起一股热潮。与OpenAI有深度合作的微软在BING搜索方面有了明显的收益,谷歌和百度等搜索引擎和互联网巨头纷纷发布各自的大语言模型(LLM)。在这些热潮的背后是GPU芯片的疯狂购买囤货,因为训练LLM需要庞大的算力支持。要支撑这类AI大模型的训练和基于这些模型的AIGC应用,需要投入数十亿美元的资金,同时还需要巨大的电力供应,因为算力强大的GPGPU耗电量也十分惊人。
据统计预测,全球算力需求呈现高速发展态势。2021年,全球计算设备算力总规模达到615EFLOPS(每秒一百京次(=10^18)浮点运算);到2025年,全球算力规模将达6.8 ZFLOPS(每秒十万京(=10^21)次的浮点运算),与2020年相比提升30倍;到2030年,有望增至56ZFLOPS。算力翻倍时间在明显缩短,大模型出现后,带来了新的算力增长趋势,平均算力翻倍时间约为9.9个月。
伴随着算力的提升,数据中心和AI服务器的耗电量也大幅提升。2022年Intel第四代服务器处理器单CPU功耗已突破350瓦,英伟达单GPU芯片功耗突破700瓦,AI集群算力密度普遍达到50kW/柜。根据ChatGPT在使用访问阶段所需算力和耗电费用估计,使用英伟达DGX A100服务器的标准机柜需要542台(每台机柜的功率为45.5kw),折算为每日电费大约4.7万美元。
对国内AI应用企业来说,即便资金不是问题,能否购买到最先进的GPU芯片也是个大问题。即便部署了足够的GPU和服务器机柜,日常运营的耗电成本也不容小觑。尽管最近两年有不少国产GPU初创公司发布性能不错的GPU芯片,但到目前为止还难以跟英伟达的GPU相提并论。面对算力和能耗这两大挑战,国产AI芯片公司能否想出“出奇”之道?
“存算一体”技术可以解决传统冯诺伊曼架构处理器所面临的三堵墙:存储墙、能耗墙、编译墙。存算一体架构没有深度多层级存储的概念,所有的计算都放在存储器内实现,这就从根本上消除了因为存算异构带来的存储墙及相应的额外开销;存储墙的消除可大量减少数据搬运,不但提升了数据传输和处理速度,而且能效比得以数倍提升,这意味着支持与传统架构处理器同等算力所需的功耗可以大大降低;存储和计算单元之间的调用和数据搬运需要复杂的编程模型,而存算一体的数据状态都是编译器可以感知的,因此编译效率很高,可以绕开传统架构的编译墙(生态墙)。
在存算一体这一赛道上,最早是美国的Mythic公司在2010年左右推出了存算一体芯片,国内在2017年左右出现了存算一体技术路径的创业团队,到现在为止已有数家,比如知存科技、千芯科技、苹芯科技、九天睿芯、后摩智能和亿铸科技等。但这些初创公司在存储器的选择上出现了三种主要方向,最早从传统存储器开始,如Flash,SRAM再到新型忆阻器ReRAM。算力也从微小算力(<1T)、500T到1P的大算力。
存算一体最大的优势在于高能效比,但微小算力场景与大算力场景最大的应用区别是对计算精度要求的满足及成本。这也决定着这些存算一体初创公司通向了不同的应用场景,比如九天睿芯的芯片产品主要面向小算力的边缘和端侧应用。而ChatGPT等大模型的出现势必对AI大算力芯片提出新的要求。
基于“存算一体”架构开发的AI芯片在克服能耗挑战方面有很大的潜力,但如何实现高性能和大算力呢?
存算一体+chiplet也许是一种可行的“出奇”之道。
在传统冯诺依曼计算架构中,占据主要地位的DRAM和Flash等传统存储技术面临技术瓶颈,面对低功耗和高性能的需求,无法实现根本性的改善,而新型存储技术成为业界重点布局与探索的方向。经过10多年的努力,MRAM(磁性存储器)、PCRAM(相变存储器)、FRAM(铁电存储器)和ReRAM(阻变存储器)等新型存储技术也逐步走出实验室,进入试用甚至商用阶段。
ReRAM(阻变存储器,或忆阻器)是以非导性材料的电阻在外加电场作用下,在高阻态和低阻态之间实现可逆转换为基础的非易失性存储器。ReRAM包括许多不同的技术类别,比如氧空穴存储器(OxRAM)、导通桥联存储器(CBRAM)等。ReRAM的单元面积极小,可做到4F²,读写速度是NAND Flash的1000倍,同时功耗可降低10倍以上。
由于电阻切换机制基于金属导丝,Crossbar ReRAM(CBRAM)单元非常稳定,能够承受从-40°C到125°C的温度波动,写周期为1M+,在85°C的温度下可保存10年。从密度、能效比、成本、工艺制程和良率各方面综合衡量,ReRAM存储器在目前已有的新型存储器中具备明显优势。
基于导通桥联的ReRAM具有高达1000倍的低/高阻态差异,使其不易受外界运行环境的干扰影响,具有很强的稳定性。同时,以ReRAM组成的存算阵列单元因为阻态区分度大,所实现的存内计算可以更好地满足大算力应用场景对算力、精度、能效比和可靠性的严格要求。
ReRAM以其密度增长空间大、生产工艺与CMOS兼容等优势,吸引了国内外众多IP技术企业、大型晶圆代工厂、传统存储企业和半导体初创企业投入到其商业化进程中。目前,台积电、联电、Crossbar、昕原半导体、松下、东芝、索尼、美光、海力士和富士通等厂商都在积极开展ReRAM技术的研究和产业化推进。国内新型存储器ReRAM的生产工艺及产线已经实现了规模化量产商用。
基于ReRAM工艺的芯片主要用于存储和存算一体两个方面,其中采用”存算一体“结构和技术的AI芯片将有可能实现AI大算力突破,成为可以应对AIGC大算力挑战的GPGPU有力竞争者,有望在AIoT、智能汽车、数据中心和高性能计算等方面获得广泛的应用。存算一体AI芯片初创公司亿铸科技基于忆阻器这种新型存储器件,创新性地采用全数字化的实现方式,将存算一体架构应用于AI大算力芯片,从而让存算一体真正在高精度、大算力AI方向实现商用落地。
由于AI模型规模不断扩大,用于深度学习的存内计算 (IMC) 单芯片方案在芯片面积、良率和片上互连成本等方面面临着巨大挑战。存算一体AI芯片能否借助芯粒(chiplet)和2.5D/3D堆叠封装技术实现异构集成,从而形成大型计算系统,提供超越单一架构IMC芯片的大型深度学习模型训练和推理方案?
美国亚利桑那州立大学的学者于2021年发布了一种基于chiplet 的IMC架构基准测试仿真器SIAM,用于评估这种新型架构在AI大模型训练上的潜力。SIAM集成了器件、电路、架构、片上网络(NoC)、封装网络(NoP)和DRAM访问模型,以实现一种端到端的高性能计算系统。
SIAM 在支持深度神经网络 (DNN) 方面具有可扩展性,可针对各种网络结构和配置进行定制。其研究团队通过使用 CIFAR-10、CIFAR-100 和 ImageNet 数据集对不同的先进DNN进行基准测试来展示SIAM的灵活性、可扩展性和仿真速度。据称,相对于英伟达V100和T4 GPU,通过SIAM获得的chiplet +IMC架构显示ResNet-50在ImageNet数据集上的能效分别提高了130和72。
上图显示了SIAM使用的基于同构chiplet的IMC架构。整个架构由一系列chiplet组成,其中包括IMC计算单元、全局累加器、全局缓冲区和DRAM。Chiplet阵列利用封装上网络(NoP)实现互联。SIAM支持基于SRAM或RRAM的IMC Crossbar存算单元,这些存算单元阵列组成处理元素(PE);PE阵列又构成IMC Tile阵列,然后构成IMC chiplet。
尽管SIAM仿真器仅针对同质架构或定制架构,但为异构集成实现的存算一体+Chiplet架构提供了很有价值的设计思路。就存算一体、Chiplet和2.5D/3D先进封装技术的发展而言,国内厂商跟国外同行基本处于同一起跑线上。在兼容CMOS的国产ReRAM工艺上,通过Chiplet和先进封装集成IMC单元、GPU和CPU等不同工艺节点的处理单元,来实现大算力AI芯片以应对算力和功耗的挑战,看来是可行的。
有业界专家总结出AI算力增长的阶段性曲线,自2018年至今的GPGPU和AI芯片算力增长属于第一增长曲线阶段。这一阶段的参与者有英伟达和AMD等国际GPU巨头,也有众多国内厂商参与其中,包括百度昆仑芯、华为海思、天数智芯、寒武纪和壁仞科技等。
这些公司所采用的晶圆工艺从14nm到5nm不等;算力从130T到485T;功耗从70W到150W。这一阶段的AI芯片的共同点在于都是采用传统的处理器架构,伴随着算力的提升,功耗和成本也随之上升。工艺节点到了5nm,一颗芯片的研发成本以亿美元计算,不是每一家公司都能够支撑得起的。即便有这个实力可以继续支撑下去,但算力与功耗的矛盾也是难以解决的,因为处理器架构在本质上决定了其局限性。
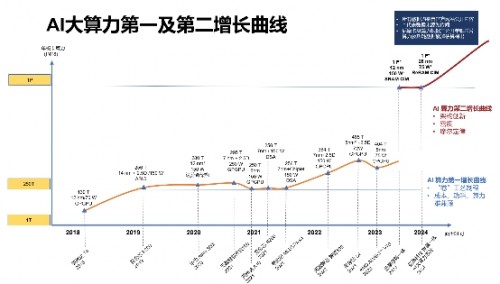
对于国内厂商来说,要在成熟工艺上以低成本实现500T以上的算力,就必须采用“出奇“的架构。存算一体+chiplet组合似乎是一种可行的实现方式,据称亿铸科技正在这条路上探索,其第一代存算一体AI大算力商用芯片可实现单卡算力500T以上,功耗在75W以内。也许这将开启AI算力第二增长曲线的序幕。


















 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>