Qzone
Qzone
 微博
微博
 微信
微信
在并不平凡的2023年,天极网与大家一起见证数智化技术赋予时代的深刻变革。以智算中心场景为例,大模型训练及推理在使智能算力需求激增的同时,也对AI集群网络性能提出更为严苛的要求,高吞吐、大带宽、高可用已成为新一代智算中心网络建设的特性......
致敬数智化时代,第二十二届IT影响中国深入挖掘行业创新价值、倾听消费者心声,评选出具有行业代表价值的科技产品及解决方案,见证数智时代的科技创新。经评委会综合评定,第二十二届IT影响中国特授予锐捷AI-FlexiForce智算中心网络解决方案以“年度影响力解决方案奖”。

随着AIGC技术赋能产业持续升级,AI大模型算力消耗惊人,单一计算设备已远远无法满足模型训练的算力需求,尽管分布式训练可以通过多个GPU节点并行训练,但随着AIGC快速发展,模型参数数量不断飙升,AI集群的GPU节点数也在不断增加,瓶颈也越来越突出。在这个背景下,GPU利用率成为提升AI大模型训练速度的主要保障,而影响GPU利用率的关键因素之一就是网络通信效率。
那么,影响网络通信效率的因素抛开硬件性能的限制,针对端处理时延、内部排队时延和丢包重传时延三大动态因素优化网络拥塞和时延,已经成为提升AI集群网络通信性能最具成本效益的方法。基于这些思考,锐捷网络致力于提升通信带宽利用率,降低动态时延以及实现无损的网络传输,以提升AI集群网络通信性能。2023年,锐捷网络面向下一代AI云服务的智算中心网络建设,重磅发布了锐捷网络AI-FlexiForce智算中心网络解决方案。
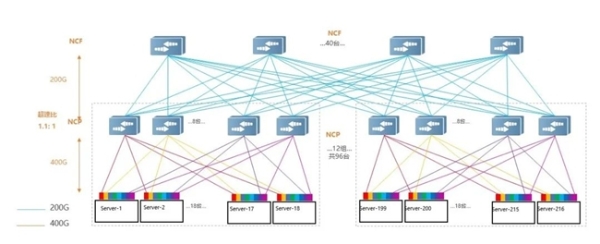
二级组网架构
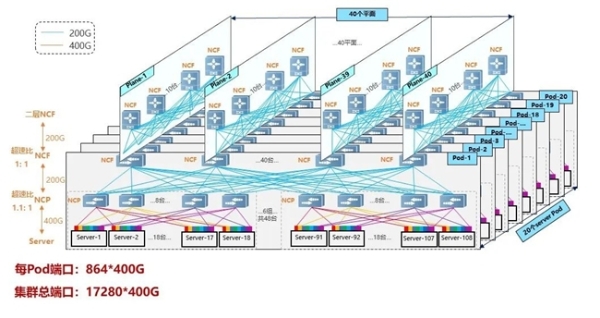
多级组网架构
锐捷网络AI-FlexiForce智算中心网络解决方案拥有高性能、高可靠、高兼容、高可用“四高”特性,可应用于大数据处理、机器学习、AIGC多种业务场景,帮助客户构建万卡级别的智算中心网络。
高性能
支持大规模组网:采用NCP+NCF为基础模块的三级多轨网络架构,三级组网可承载17K-32K的大规模GPU卡集群,多轨架构可将同号GPU的流量规划在同一Pod内,从而有效减少数据转发跳数,大幅降低通信时延。
高带宽利用率:基于高性能芯片技术,通过将数据流切分成等长的Cell并负载到所有链路,让数据流转发负载更均衡,将网络带宽利用率提升20%以上,从而有效降低长尾延时,保障AI集群的低延时通信。
高可靠
自闭环的无损传输:基于VOQ+Credit信令机制,主机接收端发送Credit,确保主机发送端流量在接收端不会过载,规避了RDMA对拥塞信号“事后”响应而造成的网络不确定性,真正实现了无损AI算力网络的通信。
去中心化的分布式OS:实现了控制面与管理面解耦,有效缩小故障域,设备可以独立升级,提升系统冗余性和可靠性,大幅提升了集群的稳定性。
链路故障快速恢复:基于硬件的自动故障隔离和恢复,无需软件干预和表项更新,即可实现微秒级的故障快速恢复,实现故障无丢包的网络系统。
高兼容
实现端网解耦:AI-FlexiForce网络由Credit信令控制NCP之间的流量转发,无需端侧参与流量控制,使AI网络不依赖于特定厂商的服务器/网卡的特定功能,可兼容全厂商全型号GPU方案,同时还支持不同GPU混合部署。
高可用
快速上线部署:在部署上线时,使用者无需复杂网络调参,即可实现即插即用的网络,直接进入可使用网络环境。
无需流量调度:在多任务场景下,出现网络拥塞的几率大幅增加,AI-FlexiForce网络无需流量调度器也可以实现95%以上的高带宽利用率,适配各种模型的流量。
天极网认为
锐捷网络AI-FlexiForce智算中心网络解决方案可实现即插即用的网络、支持大规模三级组网、全场景适用、负载均衡、带宽利用率达97%、us级硬件自愈等多种独特优势,助力打造集约高效的智算中心,为算力释放提供强大支撑。
AI-FlexiForce智算中心网络解决方案由400G NCP交换机和200G NCF交换机组成:
·NCP设备为RG-S6930-18QC40F1,提供18个400G业务口和40个200G内联口。
·NCF设备为RG-X56-96F1,提供96个200G内联口。

NCP产品RG-S6930-18QC40F1

NCF产品RG-X56-96F1
科技创新的浪潮不断奔涌向前,引领数智时代发展的新技术、新事物也不断涌现。2023年天极网也与科技企业一同感受到数智化、智能化技术的力量,尤其是大模型技术的持续发展为智算中心网络带来深刻的影响。我们注意到锐捷网络通过持续的技术研发和产品创新为智算中心带来高性能、高可靠、高兼容、高可用的AI-FlexiForce智算中心网络解决方案,赋能智算中心网络建设。荣获IT影响中国2023“年度影响力解决方案奖”,锐捷网络AI-FlexiForce智算中心网络解决方案实至名归。















 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>