




 Qzone
Qzone
 微博
微博
 微信
微信
1.概述
TTS(Text To Speech)又称语音合成,是一种将文本转化成相应语音的技术。TTS技术从诞生到现在已经有200多年的历史。在1779年,德国科学家Kratzenstein首次开发出五个长元音的人类声道模型,并于1791年加入了舌头和嘴唇模型,实现元音辅音的声道模型。随后TTS技术陷入了漫长的沉寂期,直到20世纪30年代和70年代,两大技术的突破大大推动了TTS技术的发展,1939年,贝尔实验室制作出了第一个语音合成器The Voder,1979年MIT开发出了著名的语音合成系统MITalk。1992年,PSOLA(基因同步叠加技术)的提出使合成的语音更加自然。21世纪以来,基于HMM的语音合成系统和基于神经网络的语音合成系统逐渐成为研究主流,并取得良好的效果。目前,TTS已广泛应用到日常的生活当中,如语音助手、智能音箱、地图导航等。
2.TTS系统现状
对于早期的语音合成系统来说,只要发音清晰,内容流畅并完全可懂就可以算是一个优秀的系统了。但是随着时代发展,技术的进步以及应用场景的细化,这类系统已经远远不能满足人们的需求。目前业界的TTS系统主要分为通用性TTS,个性化TTS,情感TTS三类。
通用性TTS:这类TTS系统基本已经达到可以商用的地步了,但是由于依旧存在机械感,不能模拟自然人声的原因,如果用户预期较高的话很难满足用户需求。
个性化TTS:在特定的应用场景下这类TTS系统基本能满足商用,但是效果没有通用TTS好。目前以科大讯飞为代表的人工智能企业具备成熟商用所需的技术能力。
情感TTS:随着TTS技术的发展和数据量逐渐增多,业内研究机构逐步开启了情感TTS合成技术研究。情感TTS系统的开发更加侧重于自然语言处理方面,如“情感意图识别”、“情感特征挖掘”等技术。情感TTS比传统的TTS节奏性更强,自然性也更好,但就应用落地来说还处于初步阶段。
无论对于哪种TTS系统来说,在技术相差不大的情况下,声优质量和数据量尤为重要。目前对于TTS系统来说问题之一是数据缺乏,尤其是个性化TTS对于数据量的要求更大,另一方面数据制作的周期长和成本高,都对TTS数据生产提出了更高的要求。下文着重在TTS数据制作方面做出介绍。
3.TTS数据制作流程
3.1语料制作
语料制作环节需遵循覆盖基本音素组合的原则,然后根据具体使用场景决定语料领域是否要有所偏重。语料的制作需要考虑语料来源、语料长度和语料的量级。语料来源可通过爬取、造句等方式生成,之后经过人工校对(去除拗口、有语病的语料),形成最终语料。语料的长度不同任务要求不同,以中文TTS数据为例,单句的长度在12-15字为宜。语料的数量要求主要取决于TTS系统的级别,简易的TTS系统要求数据量在3000-5000句之间,一般程度的系统需求数据量在15000句,更为高级的最低要求数据量就在20000句以上。
3.2录音人挑选
传统TTS对录音人要求较高,目前随着个性化TTS系统的需求量增大,TTS数据制作过程中录音人为播音专业学生的最低要求也有所放宽,甚至普通人也能参与到数据制作中。录音人的选取首先要基于TTS系统应用语种(英文、普通话、方言等)、朗读风格(播音、正常说话、童音、二次元等)和录音人性别年龄分布划定录音人范围。录音人范围确定后需要进行录音人的筛选工作,首先需要搜集录音人信息及录音小样,经过第一轮筛选挑出3-5人,然后在录音棚实际录音50-100句/人,最终经过第二轮综合筛选确定录音人,整个过程至少需要3-4周。
3.3录音环境
TTS数据对于录制环境要求严格,需要在专业录音棚中录制并严格控制噪声水平,最大限度还原发音人发音。录音过程中需要有专业录音师和监听人在场,及时矫正录音过程中的错误(如:口水声、喷麦、咂嘴等录音人引起噪音,发音错误,突发噪音等)。
3.4正式录音
正式录音开始前,监听人员需要跟录音人磨合语速风格,然后选择2-3句录音作为基准参考发音,由现场监听人员把控,每录20-30句向录音人播放基准参考发音。当录音人出现音质变化时,现场监听人员具有一票否决权,并可随时决定是够继续录音。另外,为保证录音质量,原则上录音人在录音棚时间不能超过4小时。
3.5数据标注
3.5.1文本标注
文字标注内容根据发音人实际发音做一致性标注,例如“1990-2-24”需要根据实际录音转写成“一九九零年二月二十四日”。
3.5.2音素标注
中文使用声母韵母系统标注,西文使用IPA进行标注。以中文为例,标注效果为:
原句:脑袋大就聪明吗?
音素:nao3 dai4 da4 jiu4 cong1 ming2 ma5?
音素标注会遇到错读、轻声和连续变调等典型问题,可基于下述方案解决:
读错字:标注时按照实际发音标注;
轻 声:标注时按照实际发音标注;
连续变调:遵从普通话变调规则,一不变调、三三变调
3.5.3音素切分
按照实际语音情况,标注出每个音素的起止时间点,此处对于标注员要求较高。
3.5.4词性标注
标记每个字所属词的词性,对于中文来说基本有39中词性,常见的有:a(形容词)、m(数词)、n(名词)、ns(地名)、p(介词)、j(简称略语)、d(副词)等,标注效果如下:
Eg:美国/ns 对/p 港/j 澳/j 政策/n 不/d 会/v 改变/v 。
3.5.5韵律标注
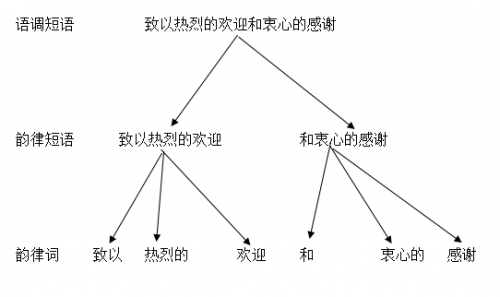
韵律又称超音段特征、节律或音律,包括节奏、强调、语调等。因为言语信息在时间线上是先后依次出现的,但实际上并不是线性平均分配,而是以层级形式分布的,所以韵律标注一般包含四级,分别为:韵律词、弱韵律短语、强韵律短语、语调短语。
韵律词:是韵律层级结构中的基本单位,指口语中紧密连在一起发音的几个音节的组合,单音节词往往会跟相邻的双音节词共同构成一个韵律词(如:“引起了”中的“了”,通常与前面的双音节词“引起”共同组成一个韵律词),包含超过三个音节的词,往往会被分解成多个双/三音节韵律词。不同韵律词边界不停顿或听感不可察觉停顿。
弱韵律短语:由一个或一个以上韵律词构成,每个弱韵律短语后有较短的停顿或静音,发音方面具有音高不下倾或稍下倾的特点。另外韵末不可以用作句末。
强韵律短语:由一个或多个弱音律短语构成,每个强韵律短语后可以感知到明显的停顿,音高曲线有明显的下倾。
注意:增加层级会增加复杂度,所以有时候会将弱韵律短语和强韵律短语作为一个层级标注
语调短语:由一个或多个强韵律短语构成,每个语调短语后会有较长的停顿且末尾音节韵律上会有延长,这种短语一般位于句末,具有特定的语调模式。语调模式的音调走势由具体的语气或句型决定,如陈述句为降调、疑问句为升调、感叹句为总体音调上升。
为了更好地理解韵律标注各个层级间的关系,我们可以下方关系图:
4.TTS系统展望
目前,合成语音的可懂度、自然度已经达到用户可接受的程度,TTS系统也已进入大规模产业化的应用阶段。随着互联网时代用户对信息获取途径的多样性需求,语音合成技术将迎来巨大的机会。例如:最近由Dessa开发出的RealTalk语音合成系统,仅需要通过输入文本即可生成堪比真人的声音,也就是说在获得足够训练数据的先决条件下,该系统可以复制任何人的声音。这项技术可能是一个重大突破,这也预示着可能在未来的十几年甚至几年,技术可能发展到只要短短几分钟的音频便可以模仿出任何一个人的声音。
语音合成技术的发展,一方面取决于技术上的进步,另一方面取决于商业化应用能否扩大市场。从技术上来说情感语音合成、个性化语音转换等是目前的研究方向,从市场角度出发,如何开发出成熟的TTS应用并获得用户认可才是关键。






安兔兔2022-05-25 20:4405-25 20:44

娱乐中国2022-05-25 20:2805-25 20:28

电影界2022-05-25 20:1905-25 20:19

电影界2022-05-25 20:1505-25 20:15

电影界2022-05-25 20:1505-25 20:15

新娱在线2022-05-25 20:1005-25 20:10

南方娱乐网2022-05-25 20:0605-25 20:06

电影界2022-05-25 19:5705-25 19:57






 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>













 京公网安备
京公网安备 网上有害信息
网上有害信息 12321垃圾信息
12321垃圾信息 北京市互联网举报
北京市互联网举报