




 Qzone
Qzone
 微博
微博
 微信
微信
随着人工智能从技术探索迈向规模化应用,数据已从“静态资源”跃升为驱动模型进化的“动态资产”。通过对数据持续的清洗、增强、标注、版本迭代,以支撑模型从预训练、微调到对齐评估的全生命周期。然而,当前大多数AI团队正深陷于数据管理的泥沼:来源分散、格式杂乱、处理流程黑盒、版本混乱等问题,导致模型效果提升无法归因,制约AI项目的研发效率与商业落地速度。
为解决这一难题,标贝科技推出新一代数据集管理平台,通过全链路数据治理能力与闭环生态设计,实现多模态数据的闭环管理,让数据真正成为可管、可看、可用的核心资产。
重塑数据管线:从混乱到秩序,从成本到资产
当前,数据管理面临结构性矛盾:一方面,模型训练对数据质量、版本可追溯性、跨模态协同的要求日益严苛;另一方面,传统的文件存储式管理方式存在显著短板:
●采集阶段:数据分散在云端、本地、边缘设备等多源异构环境,格式涵盖结构化表格、非结构化媒体文件及3D点云等特种数据,整合成本高昂;
●处理阶段:数据清洗、增强、标注等流程依赖人工脚本,每次模型迭代都需重构处理管线,导致重复劳动;
●协同阶段:多模态数据缺乏统一管理框架,视觉、文本、传感器数据无法关联分析,制约复杂场景模型开发。
标贝科技数据集管理平台区别于简单的存储工具,而是一个面向数据资产化运营的“中枢操作系统”。通过在数据储存、数据处理与模型训练之间建立清晰的映射关系,解决AI项目在数据管理上面临的采集分散、格式混乱、流程断裂、版本失控与价值孤岛等难题。
核心能力
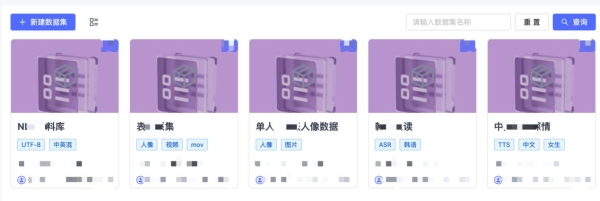
01 全模态统一存储架构
平台提供强大的统一数据湖仓能力,无论是结构化的标注表格,还是非结构化的图像、视频、音频、3D点云、传感器时序数据,均可被纳于同一逻辑视图中,实现集中收纳与规范化管理。通过标准化数据接入接口,自动适配不同来源与格式的数据,减少人工整理成本。
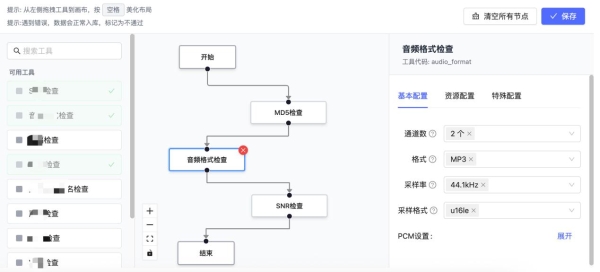
02 可视化数据处理流水线
平台将数据清洗、降噪、增强、采样、转换等处理步骤,从零散的脚本代码升级为可视化、可拖拽的流程节点。开发者无需反复编码,即可通过图形化界面灵活构建、复用和版本化管理复杂的数据处理流水线(Pipeline)。不仅降低操作门槛,更使得数据处理流程标准化、可审计,确保数据生产环节的质量与一致性。
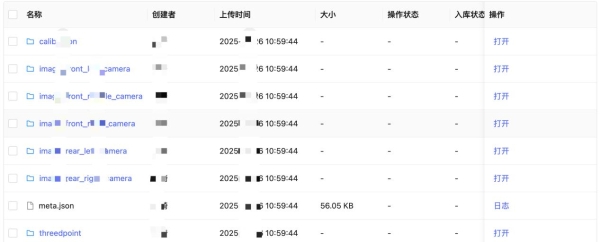
03 动态数据版本管控
平台构建了数据版本、处理流水线与模型实验间的全链路映射体系,每次数据变更均生成可追溯的版本快照,并与对应模型实验结果自动关联,实现模型表现变化的数据归因。
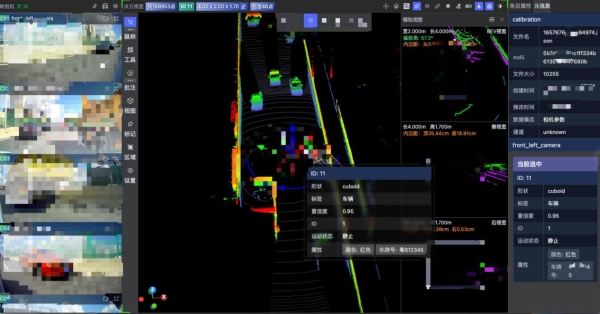
04 可视化分析与洞察
面向复杂数据场景,平台提供丰富的可视化工具,支持对数据集进行全局统计、质量分析、样本探查和标签分布。开发者不仅可以浏览单个数据样本及其元信息、标注真值,更能以融合视角审视多模态数据集的整体面貌,快速发现数据偏见、标注错误或样本不足等问题,驱动数据策略的优化。
超越管理:赋能数据闭环,驱动价值正向循环
标贝科技数据集管理平台的长期价值远不止于管理,而是作为数据驱动飞轮的核心枢纽角色,与标注平台深度打通,构建"采集-治理-应用-反馈"的完整闭环,实现数据资产的动态增值。
●自动沉淀:在标注平台完成的每一项标注任务,其产出均可自动、结构化地沉淀为平台内新的数据资产版本。
●反向指导:模型在验证集或线上环境的表现,可通过平台分析模块,反向定位到数据层面的薄弱环节,如特定场景数据不足、某类标签标注质量不均等问题。
●精准优化:基于分析结论,团队可以快速发起针对性的数据补充采集或重新标注任务,并将优化后的新数据集投入下一轮训练。
这个闭环使得数据体系不再是静态的仓库,而是一个能够伴随业务增长不断自我感知、自我诊断、自我强化的智能系统。从根本上改变了数据与模型的关系,从单向的“喂养”变为双向的“协同进化”,为企业构建了随时间推移而愈发坚固的竞争壁垒。
从短期研发效率提升到长期业务价值沉淀,标贝科技数据集管理平台不仅简化数据管理流程,更通过数据闭环,帮助客户构建起透明、高效、可持续进化的AI数据基础设施,确保将每一份数据转化为可复用、可增值的动态资产。未来,我们将持续优化平台功能,适配更多复杂场景需求,助力企业最大化挖掘数据价值,加速AI技术落地与创新突破。













联商网2026-01-28 17:0201-28 17:02






 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>



























